Displaying 47 containers
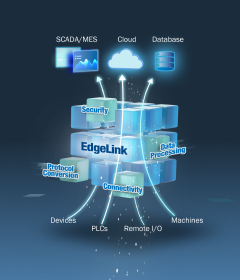 EdgeLink Docker
EdgeLink DockerEdgeLink facilitates protocol conversion and secure connections. it seamlessly connects over 200 types of OT devices with the cloud, ensuring a robust link between them.
 LLM Langchain on NVIDIA Jetson™
LLM Langchain on NVIDIA Jetson™GPU Accelerated LLM Langchain Container offers a modular, accelerated AI chat stack for Advantech GPU-accelerated devices using Ollama with multiple LLM models compatible, such as Llama 3.2 1B, FastAP
- LLM Ollama on NVIDIA Jetson™
Unlock AI on Advantech Edge with an Ollama-powered container featuring Meta Llama 3.2 1B, optimized for Jetson Orin NX with GPU passthrough, including runtime, UI, REST API—no setup needed.
- LLM Langchain AI Agent on NVIDIA Jetson™
GPU accelerated LLM AI Agent—powered by LangChain, OpenWebUI & DeepSeek LLAMA3.2-1B via Ollama. Full GPU acceleration for smart, on-device automation
- Deepseek-R1 1.5B Langchain RAG on NVIDIA Jetson™
AI-powered RAG solution for NVIDIA Jetson™! Extract insights from PDFs with DeepSeek-R1 1.5B + Langchain. Features conversational memory, tool integration & optimized performance for edge AI.
- Qwen2.5 3B AI Agent on NVIDIA Jetson™
Harness Qwen + LangChain AI Agent with EdgeSync Device Library on NVIDIA Jetson™, enabling natural language-driven control of peripherals and edge hardware via FastAPI, Ollama, and Qwen 2.5 3B.
- Deepseek-R1 1.5B Ollama on NVIDIA Jetson™
Unlock AI innovation on Advantech Edge with an Ollama-powered DeepSeek R1 1.5B container, optimized for NVIDIA Jetson™ with GPU passthrough, bundling dependencies, runtime, UI, REST API—zero setup.
- Deepseek-R1 1.5B Langchain on NVIDIA Jetson™
Power your embedded edge AI with Advantech’s GPU-accelerated container, featuring DeepSeek R1 1.5B for fast, intelligent LLM chat, tool-use, and agent workflows—perfect for smart edge deployments.
- Deepseek-R1 1.5B Llama.cpp on NVIDIA Jetson™
Enable real-time, offline AI on NVIDIA Jetson™ with DeepSeek R1 1.5B + LlamaCPP. This container delivers GPU-accelerated local inference, GGUF quantization, and modular AI workflows—no cloud needed.
 LLM Ollama + OpenClaw on NVIDIA Jetson™
LLM Ollama + OpenClaw on NVIDIA Jetson™Stop just chatting; start doing. This Jetson-optimized stack uses OpenClaw to transform Ollama into a proactive AI Agent that executes tasks and manages files across 20+ messaging channels. 🚀🤖
- Advantech YOLO Vision Applications
This is an optimized container built for running YOLO applications including image classification, object detection, instance segmentation and more, with full accelerated by GPU Advantech Devices
- GPU Passthrough on NVIDIA Jetson™
Unlock AI innovation with NVIDIA GPU passthrough–enabled container. Preloaded AI libs. No hardware or package worries—just build and deploy on Advantech Edge.

1 - 12 of 47