
Overview
Image Segmentation on Qualcomm® Hexagon™ is a comprehensive container solution for running real-time segmentation models on the QCS6490 platform. Designed with full DSP acceleration, it brings plug-and-play deployment for models like YOLOv8-seg and DeepLabv3+ MobileNet, pre-optimized for edge scenarios.
This container offers:
-
Dual Image Segmentation Workflows:
- Ultralytics Export: Use YOLOv8-native tools to export to TFLite for rapid prototyping
- AI Hub Conversion: Import optimized DeepLabv3+ MobileNet models directly from Qualcomm’s Hugging Face repository
-
Integrated Runtime Stack:
- Pre-installed support for QNN, SNPE, and LiteRT
- Includes GStreamer, OpenCV, and Python 3.10 for full inference pipeline development
-
Hardware-Accelerated Inference:
- INT8 inference on Hexagon™ DSP 770
- FP32 fallback and GPU acceleration via Adreno™ 643 GPU
-
Multi-Model Format Compatibility:
- Runs .tflite, .dlc, and .so formats natively with supported runtimes
-
Preconfigured Scripts & Utilities:
advantech-coe-model-export.shandadvantech-aihub-model-export.shfor model conversionwise-bench.shfor validating runtime and AI environment
-
Ready for Industrial Edge Use Cases:
- Built for robotics, medical imaging, automotive vision, industrial inspection, and smart agriculture
- Designed for use on Advantech AOM-2721 with QCS6490 SoC
-
Seamless ROS Support:
- Compatible with Qualcomm Robotics Reference Distro with ROS 1.3-ver.1.1 for plug-and-play robotic integration
Container Demo

Edge-Ready Use Cases
| Domain | Key Applications |
|---|---|
| Fitness & Rehabilitation | Real-time posture feedback, remote physical therapy monitoring |
| Automotive & Robotics | Scene and object segmentation for autonomous navigation and robotic interaction |
| Healthcare & Medical Imaging | Tumor/organ segmentation and quantitative analysis for diagnostics |
| Satellite & Environmental Monitoring | Land cover classification, disaster impact detection, climate analysis |
| Smart Agriculture | Crop health monitoring, yield estimation, precision weed detection |
| Industrial Inspection | Automated defect detection on parts, PCBs, and production lines |
| Retail, eCommerce & AR | Virtual try-on, product isolation, visual search, background removal |
| Photography & AR | Portrait mode, background replacement, real-time visual effects |
| Bio-Imaging & Research | Cell and subcellular segmentation for life science research |
| Marine & Environmental Science | Coral reef monitoring, shoreline mapping, erosion analysis |
Host Device Prerequisites
| Component | Specification |
|---|---|
| Target Hardware | Advantech AOM-2721 |
| SoC | Qualcomm® QCS6490 |
| GPU | Adreno™ 643 |
| DSP | Hexagon™ 770 |
| Memory | 8GB LPDDR5 |
| Host OS | QCOM Robotics Reference Distro with ROS 1.3-ver.1.1 |
| BSP | Yocto 4.0 (LE1.3) |
Container Environment Overview
Software Components on Container Image
| Component | Version | Description |
|---|---|---|
| LiteRT | 1.3.0 | Provides QNN TFLite Delegate support for GPU and DSP acceleration |
| SNPE | 2.29.0 | Qualcomm’s Snapdragon Neural Processing Engine; optimized runtime for Snapdragon DSP/HTP |
| QNN | 2.29.0 | Qualcomm® Neural Network (QNN) runtime for executing quantized neural networks |
| GStreamer | 1.20.7 | Multimedia framework for building flexible audio/video pipelines |
| Python | 3.10.12 | Python runtime for building applications |
| OpenCV | 4.11.0 | Computer vision library for image and video processing |
Quick Start Guide
For container quick start, including the docker-compose file and more, please refer to README.
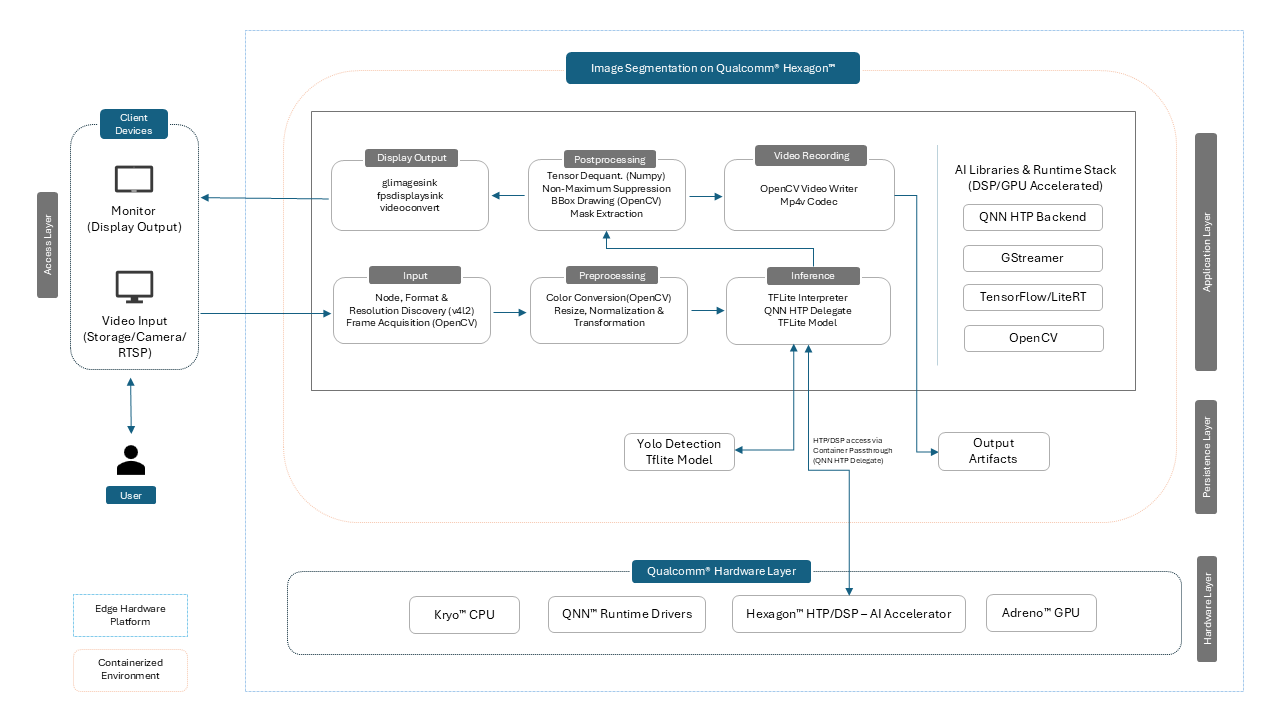
Supported AI Capabilities
Vision Models
| Model | Format | Note |
|---|---|---|
| YOLOv8 Detection | TFLite INT8 | Downloaded from Ultralytics` official source and exported to TFLite using Ultralytics Python packages |
| YOLOv8 Segmentation | TFLite INT8 | Downloaded from Ultralytics` official source and exported to TFLite using Ultralytics Python packages |
| YOLOv8 Pose Estimation | TFLite INT8 | Downloaded from Ultralytics` official source and exported to TFLite using Ultralytics Python packages |
| Lightweight Face Detector | TFLite INT8 | Converted using Qualcomm® AI Hub |
| FaceMap 3D Morphable Model | TFLite INT8 | Converted using Qualcomm® AI Hub |
| DeepLabV3+ (MobileNet) | TFLite INT8 | Converted using Qualcomm® AI Hub |
| DeepLabV3 (ResNet50) | SNPE DLC TFLite | Converted using Qualcomm® AI Hub |
| HRNet Pose Estimation (INT8) | TFLite INT8 | Converted using Qualcomm® AI Hub |
| PoseNet (MobileNet V1) | TFLite | Converted using Qualcomm® AI Hub |
| MiDaS Depth Estimation | TFLite INT8 | Converted using Qualcomm® AI Hub |
| MobileNet V2 (Quantized) | TFLite INT8 | Converted using Qualcomm® AI Hub |
| Inception V3 (SNPE DLC) | SNPE DLC TFLite | Converted using Qualcomm® AI Hub |
| YAMNet (Audio Classification) | TFLite | Converted using Qualcomm® AI Hub |
| YOLO (Quantized) | TFLite INT8 | Converted using Qualcomm® AI Hub |
Supported AI Model Formats
| Runtime | Format | Compatible Versions |
|---|---|---|
| QNN | .so | 2.29.0 |
| SNPE | .dlc | 2.29.0 |
| LiteRT | .tflite | 1.3.0 |
Hardware Acceleration Support
| Accelerator | Support Level | Compatible Libraries |
|---|---|---|
| GPU | FP32 | QNN, SNPE, LiteRT |
| DSP | INT8 | QNN, SNPE, LiteRT |
Best Practices
- Prefer INT8 quantized models for DSP acceleration
- Ensure fixed batch sizes when converting models
- Use lower
GST_DEBUGlevels for stable multimedia handling - Always validate exported models on-device after deployment
Copyright © Advantech Corporation. All rights reserved.