
Overview
About Advantech Container Catalog
The Advantech Container Catalog delivers hardware-accelerated AI containers pre-integrated for seamless edge deployment. These containers abstract complexities like SDK setup, runtime compatibility, and toolchain dependencies—offering rapid development pathways for platforms such as the Qualcomm® QCS6490 SoC.
Container Overview
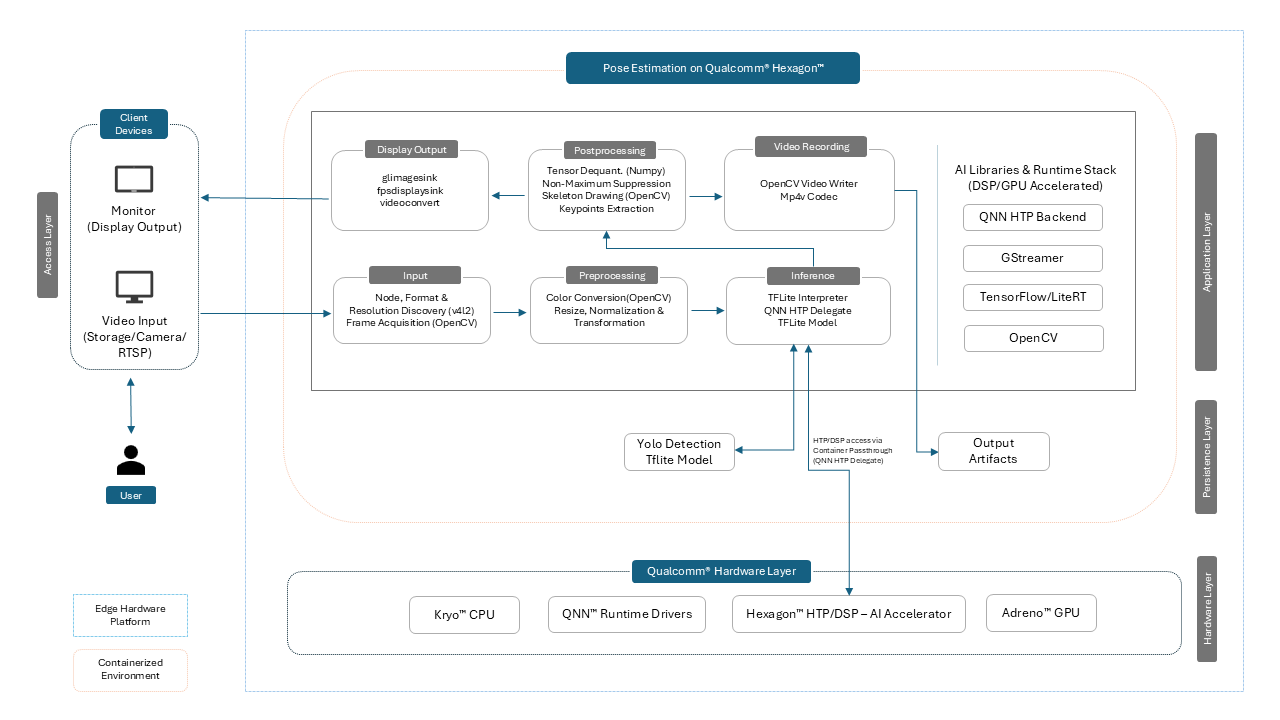
Pose Estimation on Qualcomm® Hexagon™ is a comprehensive container solution for running real-time pose estimation models on the QCS6490 platform. With full DSP acceleration, this container supports inference with models such as YOLOv8-Pose and HRNet, optimized for low-latency applications in the edge environment.
This container offers:
-
Dual Pose Estimation Workflows:
- Ultralytics Export: Use YOLOv8-native tools to export to TFLite for fast iteration and prototyping
- AI Hub Conversion: Import optimized HRNet models from Qualcomm’s Hugging Face repository for deployment-ready performance
-
Integrated Runtime Stack:
- Pre-installed support for QNN, SNPE, and LiteRT
- Includes GStreamer, OpenCV, and Python 3.10 for full pipeline development
-
Hardware-Accelerated Inference:
- INT8 inference on Hexagon™ DSP 770
- FP32 fallback and GPU acceleration via Adreno™ 643 GPU
-
Multi-Model Format Compatibility:
- Native support for
.tflite,.dlc, and.soformats across supported runtimes
- Native support for
-
Preconfigured Scripts & Utilities:
advantech-coe-model-export.shandadvantech-aihub-model-export.shfor exporting pose estimation modelswise-bench.shfor validating AI environment and runtime compatibility
-
Ready for Edge AI Use Cases:
- Tailored for robotics, fitness tracking, motion capture, smart surveillance, AR/VR, and more
- Optimized for deployment on Advantech AOM-2721 with QCS6490 SoC
-
Seamless ROS Support:
- Plug-and-play compatibility with Qualcomm Robotics Reference Distro (ROS 1.3-ver.1.1) for robotic applications
Container Demo

Host Device Prerequisites
| Component | Specification |
|---|---|
| Target Hardware | Advantech AOM-2721 |
| SoC | Qualcomm® QCS6490 |
| GPU | Adreno™ 643 |
| DSP | Hexagon™ 770 |
| Memory | 8GB LPDDR5 |
| Host OS | QCOM Robotics Reference Distro with ROS 1.3-ver.1.1 |
Container Environment Overview
Software Components on Container Image
| Component | Version | Description |
|---|---|---|
| LiteRT | 1.3.0 | Provides QNN TFLite Delegate support for GPU and DSP acceleration |
| SNPE | 2.29.0 | Qualcomm’s Snapdragon Neural Processing Engine; optimized runtime for Snapdragon DSP/HTP |
| QNN | 2.29.0 | Qualcomm® Neural Network (QNN) runtime for executing quantized neural networks |
| GStreamer | 1.20.7 | Multimedia framework for building flexible audio/video pipelines |
| Python | 3.10.12 | Python runtime for building applications |
| OpenCV | 4.11.0 | Computer vision library for image and video processing |
Quick Start Guide
For container quick start, including the docker-compose file and more, please refer to README.
Supported AI Capabilities
Vision Models
| Model | Format | Note |
|---|---|---|
| YOLOv8 Detection | TFLite INT8 | Downloaded from Ultralytics` official source and exported to TFLite using Ultralytics Python packages |
| YOLOv8 Segmentation | TFLite INT8 | Downloaded from Ultralytics` official source and exported to TFLite using Ultralytics Python packages |
| YOLOv8 Pose Estimation | TFLite INT8 | Downloaded from Ultralytics` official source and exported to TFLite using Ultralytics Python packages |
| Lightweight Face Detector | TFLite INT8 | Converted using Qualcomm® AI Hub |
| FaceMap 3D Morphable Model | TFLite INT8 | Converted using Qualcomm® AI Hub |
| DeepLabV3+ (MobileNet) | TFLite INT8 | Converted using Qualcomm® AI Hub |
| DeepLabV3 (ResNet50) | SNPE DLC TFLite | Converted using Qualcomm® AI Hub |
| HRNet Pose Estimation (INT8) | TFLite INT8 | Converted using Qualcomm® AI Hub |
| PoseNet (MobileNet V1) | TFLite | Converted using Qualcomm® AI Hub |
| MiDaS Depth Estimation | TFLite INT8 | Converted using Qualcomm® AI Hub |
| MobileNet V2 (Quantized) | TFLite INT8 | Converted using Qualcomm® AI Hub |
| Inception V3 (SNPE DLC) | SNPE DLC TFLite | Converted using Qualcomm® AI Hub |
| YAMNet (Audio Classification) | TFLite | Converted using Qualcomm® AI Hub |
| YOLO (Quantized) | TFLite INT8 | Converted using Qualcomm® AI Hub |
Language Models Recommendation
| Model | Format | Note |
|---|---|---|
| Phi2 | .so | Converted using Qualcomm's LLM Notebook for Phi-2 |
| Tinyllama | .so | Converted using Qualcomm's LLM Notebook for Tinyllama |
| Meta Llama 3.2 1B | .so | Converted using Qualcomm's LLM Notebook for Meta Llama 3.2 1B |
Supported AI Model Formats
| Runtime | Format | Compatible Versions |
|---|---|---|
| QNN | .so | 2.29.0 |
| SNPE | .dlc | 2.29.0 |
| LiteRT | .tflite | 1.3.0 |
Hardware Acceleration Support
| Accelerator | Support Level | Compatible Libraries |
|---|---|---|
| GPU | FP32 | QNN, SNPE, LiteRT |
| DSP | INT8 | QNN, SNPE, LiteRT |
Best Practices
- Prefer INT8 quantized models for DSP acceleration
- Ensure fixed batch sizes when converting models
- Use lower
GST_DEBUGlevels for stable multimedia handling - Always validate exported models on-device after deployment
Copyright © Advantech Corporation. All rights reserved.